PyConJP2022参加メモ
10/14-15にかけてPyConJP2022に参加しました。今更ですが参加メモです。
2019年に蒲田で参加して以来のオンサイト参加でした。
TOC有明は初めてでしたが、アクセス設備共によかったと思います。今後も有明でいいかも‥?

1日目
Pythonとアスタリスク https://2022.pycon.jp/timetable?id=LPYF7C
・Pythonにおける「*」の文法事項の一覧、Tipsの紹介
⇒アンパック演算子、専用|可変長引数 etc
・『5つのLTをくっつけた発表』とのことだったので、こういう発表の仕方もあるのかと参考になった。
・発表資料がGithub Pages。ナウい。
実践:日本語文章生成 Transformersライブラリで学ぶ実装の守破離 https://2022.pycon.jp/timetable?id=EEA8FG
・日経新聞社における文書生成技術の紹介
・本文から見出しを自動生成するBERTモデルの構築
例:画像参照。 本文から見出しを生成する様子。本文中に「諮問」というワードはないが、自動生成されている。

・huggingface社のTransformersライブラリ(自然言語処理)を利用
O'Reilly Japan - 機械学習エンジニアのためのTransformers
・streamlitを使ってpandas.DataFrameをWebアプリとしてホストできる仕組みを利用
Streamlit • The fastest way to build and share data apps
⇒試しに使ってみましたが非常に便利でした。色々制約はありますが、大抵のことはstreamlitで用足りる気がします。
2日目
基調講演: 西内 啓氏 https://2022.pycon.jp/timetable?id=HFEB37
・データサイエンスをすべての人に
・DataVehicle社を立ちあげ、dataDiverを作った
・dataDiverは、BIツールではなく「拡張アナリティクス」。人間のデータ分析の営みを拡張することが目的
・「拡張アナリティクス」という分野での国際シェア1位はDataRobot。国内シェア1位はdataDiver。
・dataDiverは仮説探索マシン。非線形な分布や変数が爆発しそうな場合はpandasなど
・(※質疑応答の中で)データ分析会社の財産は事業会社とのリレーションと考えている
・最近アクセンチュアがAIベンチャーのアルベルトを買収した。
⇒コンサル会社の風土などが合わず、社員が辞めていった場合どうなってしまうのかが興味ある、とのこと
Pythonではじめる地理空間情報 https://2022.pycon.jp/timetable?id=PCBGF8
・3D都市空間はデジタルツイン(≠メタバース)。現実世界をコピーした仮想空間
・位置情報の要素は「ポイント(点)、ライン(線)、ポリゴン(面)」
・地球は丸くない。山、谷があるので表面は凸凹。
・geemapとleafmap(geemapのスピンオフ)はGoogleColab、JupyterNotebook上で動作するオープンソースのPythonパッケージ
geemap · PyPI
・現時点では公的機関向けの活用が主。都市のデジタル化の根幹をなす街づくりのためのデータが現在急速に進んでいる。
例:My City Forecast あなたのまちの未来予報
現状の人口分布・施設配置データをもとに、2015年~2040年に想定される居住地域の環境を可視化するシミュレーションサービス
My City Forecast あなたのまちの未来予報
SQL クエリ解析による E2E データリネージの実現 https://2022.pycon.jp/timetable?id=QRYKXS
・stairlightというデータリネージツールの作者による発表。
stairlight · PyPI
・データリネージ:データの系譜を明らかにすること。メタデータの一種
・dbtとの違い:リネージする対象の範囲
・dbtはETLにおけるtransform部分を主に対象とするが、stairlightはダッシュボード部分のSQLなども取得できる。範囲の広さが売り。
・内部ではSELECT文を探索するシンプルなつくり。ただし循環参照や探索深度などの課題があるので、各種アルゴリズムを使い解決している
感想
・テーマが多岐に渡っていたのでとても刺激になりました。
・個人的にはstreamlitが目から鱗でした。ちょっと使ってみましたがとてもいいものでした。
・動画映えもする模様。
【超簡単Webアプリ】streamlitでWebアプリを最速で作ってネット公開!〜 プログラミング初心者向け 〜 - YouTube
【Section1: Streamlitの概要】【Streamlit+Colab】人工知能Webアプリを手軽に公開しよう! -Udemyコースを一部無料公開- #airslab - YouTube
・展示ブースも結構出ていて、コロナ禍を感じさせない雰囲気でした。
・PythonEDの吉政さんがガラポン係をされていたのでなんと贅沢な‥と思ってました



Amazon ionフォーマットのデータをAthenaでクエリしてみた
Amazon ionとは
Ion は、Amazon 内部で独自に開発された、オープンソースでリッチタイプの自己記述型階層データシリアル化フォーマットです。Ion は、構造化データと非構造化データの両方を一緒に保存する抽象データモデルに基づいています。
・型指定できるJSONフォーマットという印象です。
・数値型の精度、timestampのタイムゾーンなど細かな指定が可能
・リスト、辞書、S式といったデータも格納可能
・型情報のアノテーションを付与可能で、処理時に型を検証させることが可能
・スキーマレス
Amazon QLDB での Amazon Ion データ形式リファレンス - Amazon Quantum Ledger Database (Amazon QLDB)
Amazon Athena が Amazon Ion データのクエリのサポートを追加
利用シーン
・QLDB等で利用されている台帳データをs3へ出力し、ionフォーマットで読み込みデータカタログ化した後、Athena等で解析可能とする 等
→監査ログなどの半構造化データとS3に保管されている他データとの活用が実施しやすくなる


https://pages.awscloud.com/rs/112-TZM-766/images/Session3%20-%20%E4%B8%80%E6%AD%A9%E8%B8%8F%E3%81%BF%E8%BE%BC%E3%82%93%E3%81%9F%E3%82%99Amazon%20QLDB%E3%81%AE%E5%88%A9%E7%94%A8%E6%96%B9%E6%B3%95.pdf
やってみた
・ionフォーマットのファイルを用意し、Glue CrawlerでGlueDataCatalogへデータカタログを作成したうえで、Athenaよりクエリ可能かを検証しました。
amzn.github.io
1.ionフォーマットのファイルを用意し、S3へ配置
{data: annot::{foo: null.string, bar: ( 'a' 'b' 'c' )}, time: 2022-04-17T20:30Z}
2.1.のデータを読み込めるGlue Crawlerを作成しデータカタログを作成
・クロールさせたところ、DataCatalogは作成できましたが、入出力形式およびSerde シリアル化ライブラリの指定がされていなかったので手動で追加しました。
(左が変更前、右が変更後 ※上下中央辺りの項目を変更)

・struct型の中身もチェックしてくれますが、型や精度は正確でない場合がありました(体感)。
→fooカラムについて、値はnullですが型はStringとして認識されています。

Using CREATE TABLE to Create Amazon Ion Tables - Amazon Athena
Using a SerDe - Amazon Athena
3.Athenaよりクエリを実行し、結果を取得
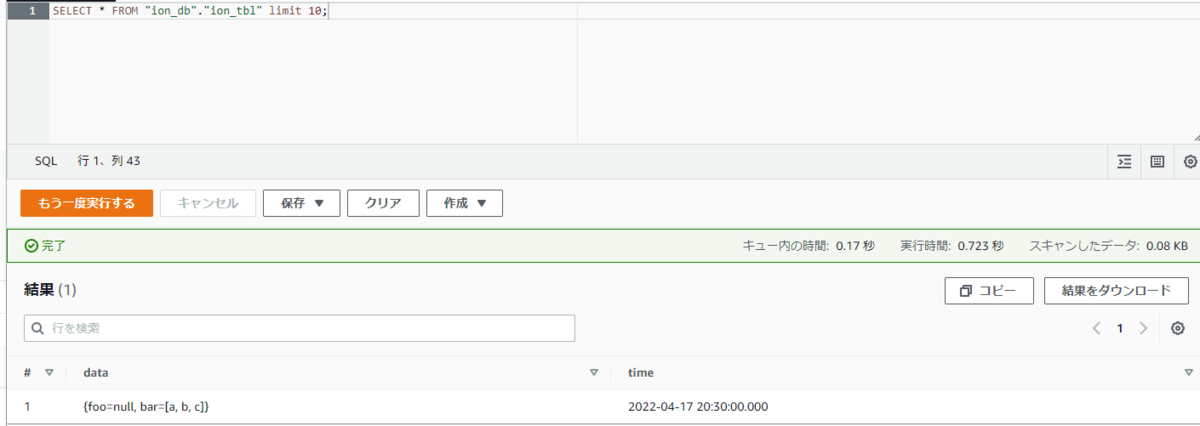
・S式(sexp)型は、マネコンよりGlueDataCatalogへ指定できなかったので、未検証
・参考までにDDLを張っておきます。 ※データベース名、テーブル名は適当です
CREATE EXTERNAL TABLE `ion_tbl`( `data` struct<foo:string,bar:array<string>> COMMENT '', `time` timestamp COMMENT '') ROW FORMAT SERDE 'com.amazon.ionhiveserde.IonHiveSerDe' STORED AS INPUTFORMAT 'com.amazon.ionhiveserde.formats.IonInputFormat' OUTPUTFORMAT 'com.amazon.ionhiveserde.formats.IonOutputFormat' LOCATION 's3://[BucketName]/ion_db/ion_tbl/' TBLPROPERTIES ( 'CrawlerSchemaDeserializerVersion'='1.0', 'CrawlerSchemaSerializerVersion'='1.0', 'UPDATED_BY_CRAWLER'='ion_test', 'averageRecordSize'='83', 'classification'='ion', 'compressionType'='none', 'objectCount'='1', 'recordCount'='1', 'sizeKey'='83', 'typeOfData'='file')
感想
・割とすんなり使えました。
・ionフォーマットの利点があまり見えてこないので、AWS社内事例なんかを聞いてみたいです。
→avro、parquet等のフォーマットではなくionである理由。 スキーマ情報は欲しいがカラムナフォーマットではなく、性能面で有利なフォーマット?
備考
・現在(2022/4/17時点)での検証結果です。
・GlueのDynamicFrameではionフォーマットは扱えないようです。
AWS Glue での ETL 入力および出力の形式オプション - AWS Glue
→AWS DataWrangler等を使ってAthena越しにデータ参照するしかなさそうです。
Quick Start — AWS Data Wrangler 2.15.0 documentation
・Athenaでionフォーマットを扱えるようになったことで、QLDBのジャーナルデータをAthenaから変換無しでクエリできるようになったようです。
Amazon QLDBのジャーナルデータがJSONエクスポート出来るようになったので、QuickSightで集計してみた | DevelopersIO
AWS IoT EduKitセットアップメモ
AWS IoT EduKitでLチカするまでのセットアップ手順を進めるにあたって、詰まったところのメモです。


1.開始方法
(1)Git Clone先のフォルダ名
全角文字が入っているとコンパイル時にフォルダ名が文字化けして前に進めなくなるので、フォルダ名は半角文字のみにします。
(2)Silicon Labs USB to UART bridgeのセットアップ(Windows10の場合)
公式サイトからダウンロードした場合、exeファイルが同梱されていないので、.infファイルからインストールします。
「silabser.inf」を右クリック>インストール可能です。
⇒後から気づきましたがM5Stackのダウンロードページにexeファイルありのzipファイルがあったので、そちらから取得する方がいいと思います。
https://docs.m5stack.com/en/download
(3)RainMaker Agent ファームウェアのビルドとアップロード
コンパイルに時間がかかり、失敗する場合は(1)が原因である可能性があります。
成功した場合は下記のような結果となります。

QRコードを表示した状態

2.Lチカ
(1)ESP32 ファームウェアの設定
・VSCode上のターミナル(PowerShell)だとKconfig操作時に矢印キーが受け付けてくれなかったので、「/」から各メニュー項目を入力して選択しました。PlatformIO側で予測変換が効いてくれるので楽でした。
端末はSurfaceProです。タイプカバーの問題…?

もともと在宅勤務時の便利グッズを作ろうとしてたのですが、チュートリアルをこなして満足してしまっていました。
もっと活用しようと思います…!
TreasureDataのデータをTreasureWorkflowを利用してS3へエクスポートする
TreasureData内のテーブルデータをTreasureWorkflow(≒DigDag)を利用してS3へエクスポートする際、若干ハマったので備忘録として残します。
■したいこと
TreasureDataに保管しているデータを、S3へ出力する
⇒本記事の内容はtdオペレータ(td table:exportコマンド)を使うのではなく、td_table_exportオペレータを使用してデータを出力する場合です。
記事作成時点ではバージニアリージョンでしか利用できないので注意
東京リージョンでも利用できるようになったようです(2021/06/09追記)
docs.treasuredata.com
github.com
■エクスポートまでの流れ
1.TresureWorkflow定義ファイル作成(.digファイル作成)
https://docs.digdag.io/operators/td_table_export.html
+step1: td_table_export>: database: mydb table: mytable file_format: jsonl.gz from: 2016-01-01 00:00:00 +0800 to: 2016-02-01 00:00:00 +0800 s3_bucket: my_backup_backet s3_path_prefix: mydb/mytable
保管先のS3バケットが「SSE-KMS」の場合は下記オプションも追加する必要があります。(SSE-Cの場合は不明)SSE-S3の場合は不要でした。
use_sse: true sse_algorithm: AES256
2.1.の定義ファイルを、td wf pushコマンドを使用してTreasureDataに登録します。
3.td wf secretsコマンドを使用してAWS接続用のsecretを設定します。
⇒アクセスキーIDとシークレットアクセスキーを指定する。同じ.digファイル内でtdコマンドでresult_connectionオプションを利用してデータをエクスポートしている場合は、そちらの設定が優先されるので注意
Run a Query and Download Results - Product Documentation - Treasure Data Product Documentation
4.td wf runコマンドを使用してTreasureWorkflowを実行します。
■総括
わからないことがあったらTreasureDataのチャットですぐに聞きましょう。
⇒即レスしていただけるので、ネットを漁る前に聞いた方がいいです。

Contacting Technical Support - Product Documentation - Treasure Data Product Documentation
不要なLambdaレイヤーをワンライナーで削除する
故あってAWS環境のお掃除をすることがあり、その時にめんどくさい思いをしたのでメモです。Windows環境(コマンドプロンプト)で実施しています。
1.tl;dr (※Lambdaレイヤー全バージョン一括削除ワンライナー)
for /l %i in (1,1,100) do (aws lambda delete-layer-version --layer-name 【Lambdaレイヤー名】 --version-number %i --profile=【環境名】)
※100は適当です。現存するレイヤーバージョン以上指定していればOKです。範囲外の値を指定しても特に怒られなかったです。
2.えるしっているか Lambdaレイヤーは1バージョンずつしかけせない
Lambdaレイヤーは1バージョンずつしか削除できません(再掲)。
なのでマネコンからひたすらポチポチするか、CLIの「aws lambda delete-layer-version」コマンドを外から回してあげるしかないです。
Layerの作り方にもよりますが、開発を進めていると50とか100とかになっているときもあるので、手作業での削除はつらみを感じると思います*1
CLIの場合、戻り値はないっぽいので結果は素直にマネコンを見るかCLIで確認してください。
コマンド(ワンライナー)は下記です。Lambdaレイヤー名と環境名は書き換えてください。
for /l %i in (1,1,100) do (aws lambda delete-layer-version --layer-name 【Lambdaレイヤー名】 --version-number %i --profile=【環境名】)
あと無駄にbatファイルも用意してしまったので、そちらも供養のため貼っておきます。
@ECHO OFF
setlocal enabledelayedexpansion
cd %~dp0
pause
for /l %%i in (1,1,100) do (
set increment=0%%i
echo !increment!
aws lambda delete-layer-version --layer-name 【Lambdaレイヤー名】 --version-number !increment! --profile=【環境名】
)
pause
3.AWS環境のお掃除について(ポエム)
・ただのお掃除とはいえ結構いろんなところで躓きます(VPCが消えない、Roleの削除順を間違えて削除できなくなる等)。 ただ以前(2年前くらい?)に比べると逃げ道が色々用意されるようになってきていると感じます(※CFnにおけるリソース削除をスキップする機能、ENI強制デタッチ機能などなど)
・個人で使う分にはアカウントごと入れ替えればいいですが、そうもいかない場合はお掃除を実施する必要があるので、お掃除手段が増えたことは普通にありがたいなーけどめんどくさいなー…と思いながらS3バケットを空にする作業に勤しむ今日この頃です。*2
■参考
https://www.366service.com/jp/qa/483db1e26b8dd6b23a783f97129e3c09
CodeBuildのIPガチャを回避するお話
CodePipelineからCodeBuildを呼び出してDockerイメージを作成しデプロイする際、DockerHubの匿名ユーザによるAPI呼び出し制限に引っかかってビルドエラーが頻発する現象が発生しました。
toomanyrequests: You have reached your pull rate limit. You may increase the limit by authenticating and upgrading: https://www.docker.com/increase-rate-limit
クラスメソッド様のブログを参照して『DockerIDを取得しユーザー認証する設定』を実施しました。しかしDockerクソ雑魚勢の私にはハードルが高く色々詰まってしまったので、1から設定する手順をここに残します。
“Too Many Requests.” でビルドが失敗する…。AWS CodeBuild で IP ガチャを回避するために Docker Hub ログインしよう!という話 | Developers.IO
目次
- 1.DockerIDの取得
- 2.CodeBuildへの環境変数追加およびパラメータストアへID・パスワードの格納
- 3.CodePipelineの修正(※実施しません)
- 4.buildspec.ymlの修正
- 5.実行
- 6.CodeBuildトラブルシュート
- 7.さいごに
前提
・CodeBuildを使用したECSのビルド環境がすでに存在している
・CodeBuildが使用するRoleに適切な権限が付与されている
→SSM、KMS、ECS、CodeBuildの各種権限が付与されていれば問題ないと思います。私はかなり強めの権限で実施したので、権限を絞っているとうまくいかない可能性はあります。
・CodePipelineを利用していなくても問題ありません
1.DockerIDの取得
(1)DockerHubよりDockerIDを取得
ID・メールアドレス・パスワードを設定します。
Docker IDの命名規約ですが、下記の制限があります。
- 長さは4文字以上30文字以下
- 数字および英小文字で構成する
しかし現在(2020/11/25)実際に入力する際に大文字でも入力でき、発行されるIDが小文字に変換された状態で発行されます。(IDに対する入力チェックがないです。。)
なのでDockerIDは上記制約に従ったIDを設定して下さい。IDが間違っているとDockerHubの認証時に下記のエラーメッセージが出力されます。
Error response from daemon: Get https://registry-1.docker.io/v2/: unauthorized: incorrect username or password
(2)ID発行後にメール検証
「[Docker Hub] Please confirm your email address」の様な件名のメールが、入力したメールアドレス宛に届くので、verifyします。
DockerHubへのログインをしたいだけなので、ここまででDockerHubの作業は完了です。IDとパスワードは次以降の手順で使用します。
2.CodeBuildへの環境変数追加およびパラメータストアへID・パスワードの格納
クラスメソッド様のブログではSecretManagerを使用されていましたが、私はお金をかけたくなかったのでParameterStore(SecureString)を使用しました。
ParameterStore(SecureString)は、CloudFormationでの作成に対応していないのでマネコンより作成します。
(※手順では画面の操作を指示しています。今後画面の配置が変わる可能性はありますが、実施したい内容は変わりません。また本手順ではCodeBuildコンソールから作成していますが、SSMから作っても問題ないはずです)
(1)CodeBuildの更新(前半)
a.CodeBuildのビルドプロジェクト画面を開く(※ビルド履歴が並んでいる画面)
b.右上「編集」より「環境」を選択
c.『AWS CodeBuild にこのサービスロールの編集を許可し、このビルドプロジェクトでの使用を可能にする』のチェックを外し、下の「追加設定」を開く (※チェックを外さないと保存できません。。)
(2)SystemsManager ParameterStoreにてパラメータの作成(SecureString)
a.「パラメータの作成」を押下し、「名前」「値」を設定します。私は下記の値を設定しました。
※クロスアカウントで実施される方はKMSを変更したほうがいいと思います。それ以外の方はデフォルトキーの方が何かと問題にならないと思います。
| 名前 | 値 |
| DOCKERHUB_USER | [DockerID] |
| DOCKERHUB_PASS | [DockerIDに対応するパスワード] |
b.パラメータを作成すると下記のようになります。パラメータ名の先頭に『/CodeBuild』が付与されます。
| ParameterStoreにおけるパラメータ名 | 値 |
| /CodeBuild/DOCKERHUB_USER | [DockerID] |
| /CodeBuild/DOCKERHUB_PASS | [DockerIDに対応するパスワード] |
■ParameterStoreの様子

(3)CodeBuildの更新(後半)
a.パラメータが作成されると、名前のない環境変数が作成されているので、環境変数の名前をそれぞれ入力したうえでページ下部の「環境の更新」を押下します。
私は環境変数名もパラメータ名に合わせたので、結果として下記のような設定値となりました。
| CodeBuild環境変数名 | ParameterStoreにおけるパラメータ名 | 値 |
| DOCKERHUB_USER | /CodeBuild/DOCKERHUB_USER | [DockerID] |
| DOCKERHUB_PASS | /CodeBuild/DOCKERHUB_PASS | [DockerIDに対応するパスワード] |
■パラメータの設定状態(CodeBuild)

■環境変数の設定状態(CodeBuild)

3.CodePipelineの修正(※実施しません)
本手順では実施しません。最初はCodePipelineから渡そうとしていましたが、過度に複雑になりそうだったのでやめました。
ただCodePipelineのパラメータで一元管理したい等の何らかの事情がある場合は、CLIからの更新でパラメータを追加すれば可能だと思います。
4.buildspec.ymlの修正
buildspec.ymlのpre_buildにコマンドを追加します。(下の末尾2行です)
--password-stdinオプションを使わないと警告が出るので下記としています。
phases:
pre_build:
commands:
- DEFAULT=`pwd`
- echo Logging in to Amazon ECR...
- aws --version
- $([※ECSへのログイン])
- echo Logging in to Docker Hub...
- echo $DOCKERHUB_PASS | docker login -u $DOCKERHUB_USER --password-stdin
5.実行
Pipelineを流し直して、CodeBuildを実行します。基本的にはうまくいくはずです。
失敗した場合は権限周りやアカウント周りを疑った方がいいと思います。パラメータの置換はうまくいっている場合が多いです(経験上)。
ユーザー認証するようになってからは「toomanyrequests」のエラーは出力されていません。

6.CodeBuildトラブルシュート
Error: Cannot perform an interactive login from a non TTY device
CodeBuildの環境変数に値が設定されていない場合に発生します。
DockerHubへのアクセスで発生した場合は、credential等の問題ではないです。
CodeBuildの環境、ビルド結果等に環境変数が設定されていることを確認してください。
参考:Solved: Piplenes: docker login can not perform an interact...
Error response from daemon: Get https://registry-1.docker.io/v2/: unauthorized: incorrect username or password
ユーザー情報が間違っています。環境変数は正しく設定されている場合が多いので、メールのアクティベーションなど実施漏れがないかを確認したほうがいいと思います。
7.さいごに
- CodeBuildはハマりどころが多くよく泣かされています(よね)
- 以前10回以上ビルドに失敗し1時間ドブに捨てたことがあるので、本手順で皆様の時間が救えれば幸いです
- ソシャゲもAWSもガチャ運なさ過ぎることがわかったのでFGO引退します
■公式・先人の知恵など
CodeBuild のビルド仕様に関するリファレンス - AWS CodeBuild
CodeBuild の Docker サンプル - AWS CodeBuild
docker login | Docker Documentation
Solved: Piplenes: docker login can not perform an interact...
Docker IDの取得方法 — Docker を用いた HPCI ログイン
“Too Many Requests.” でビルドが失敗する…。AWS CodeBuild で IP ガチャを回避するために Docker Hub ログインしよう!という話 | Developers.IO
AWS CodeBuildでビルド時に環境変数を設定する | Hack Notes
CloudWatch Metricsのグラフ画像を取得し、Lambdaより定期的にSlack通知させたい
まえがき
この手の話は、(AWSの場合は)「CloudWatch Alarm+ CloudWatch Metrics + SNS + Chatbot (+ Slack)」や「CloudWatch Alarm+ CloudWatch Metrics + SNS + DataDog(+ Slack)」という構成を第一に検討するべきだと思います。
ただし下記のケースなど、マネージドサービス利用ではなく何らかの実装で対応せざるを得ない場合があると思います。本稿ではそういったニッチな場合のお話を取り扱っている次第です。
1.CloudWatch Alarmは1つのメトリクスしか選択できない
→1つのメトリクスしか選択できないため、複数Metrics要素のグラフを作ることができない
→APIGatewayの4XX5XXエラー、Lambdaのエラー率とエラー件数の相関、Glueにおける各Executorメモリ使用量の推移などは、複数Metricsを並べることでグラフとして有意になる場合があります。
2.定期的にMetricsの状態をSlack通知したい場合、CloudWatch Alarmだと定期実行できない
→これに関しては色々逃げ道がありそうですが、基本的にはCloudWatch Alermはイベント発火なので定期実行はできないです(※投稿日時点では)。
事前準備
・SlackAppにて投稿用のSlackアプリを作成&インストール済。
→IncomingWebhookでも可能です。リクエストの形式を変更すれば大丈夫です。ただSlackAPI的に画像をそのまま渡せないので、S3に置く→S3のURLをattachments属性のimage_urlに設定する、という1クッション置いた方式となります。
・requestsモジュールを使ってます。
→urllibで頑張ろうとしましたが、つらみが深かったのでやめました。ゆるして
構成
CloudWatch Events(Cron) → Lambda(Slack通知) ←(※boto3経由)→ CloudWatch Metrics
実装
・Lambda環境変数は下記。
url・・・"https://slack.com/api/files.upload"
oauth_token・・・Slackアプリに対応するOAuthトークン
channel・・・SlackチャンネルのURLの末尾のハッシュ
・本LambdaをCloudWatch Eventsより定期実行する。
ソース(Python3.8)
import os import sys import json import boto3 import requests s3_rw = json.dumps({ "view": "timeSeries", "stacked": True, "metrics": [ [ "Glue", "glue.ALL.s3.filesystem.read_bytes", "Type", "gauge", "JobRunId", "ALL", "JobName", "TestJob", { "label": "S3 Bytes Read" } ], [ ".", "glue.ALL.s3.filesystem.write_bytes", ".", ".", ".", ".", ".", ".", { "label": "S3 Bytes Written" } ] ], "title": "[Glue][TestJob][s3 read/write][SUM][1 minute]", "stat": "Sum", "period": 60, "width": 1600, "height": 600, "start": "-P1D", "end": "P0D", "timezone": "+0900" }) cloud_watch = boto3.client('cloudwatch', region_name='ap-northeast-1') # ハンドラ def lambda_handler(event, context): # 処理対象たち cw_map = { "Glue S3書き込み/読み込み状況【1分毎・合計】": s3_rw, } for cw_title in cw_map: # CloudWatchからウィジェット画像取得 response_cw = cloud_watch.get_metric_widget_image(MetricWidget = cw_map[cw_title]) image = {'file': response_cw['MetricWidgetImage']} # Slack通知 url = os.environ['url'] params={ "token": os.environ['oauth_token'], "channels": os.environ['channel'], "title": cw_title, "filetype": "png" } req = requests.post(url, params=params, files=image) try: req.raise_for_status() except requests.RequestException as e: print(e)
ハマりポイント
・CloudWatch MetricsのイメージAPIを出力すると「true/false」で出力されるので、「True/False」へ変更する。
・イメージAPIのtitle属性に全角文字を入れると文字化けするので注意しましょう(一敗)。
・req = requests.post(url, params=params, files=image) のfiles属性に(名前的に)複数画像が添付できそうですが、できなかったです。複数画像アップロードできた方いらっしゃれば教えていただきたいですm(_ _)m
・複数回SlackへURLを投げるので、タイムアウト値は30秒程度にしたほうが良いです(※対象のCloudWatch Metricsの数によりますが)
おわりに(※ポエム)
監視アラームを設定する際にはCloudWatchにせよDataDogにせよ、基本的には何らかの閾値を設定することが求められます。
既存サービスの場合はCloudWatch anomaly detectionなどのサービスを利用すれば大体事足りますが、新規サービス案件(再構築などの案件も含む)の場合は、「仮決めした値でしばらく運用して、時が来たら変える」という感じになりがちです(※個人の感想です)。
この場合問題となるのは「想定外事象に気づけない」「正常に動作している状態が知りたいが毎日確認しにいくのは面倒(≒なんとなく大丈夫だろうという意識で運用してしまう)」という点にあります。
なので本稿のような、適度な期間での正常性確認をお手軽にできる手段があればな~と思った次第です。
(※ダッシュボードってかっこよくても結局見なくなるんで、何かしら通知させたいですよね。。ダッシュボードが来い)
(※Slack Command1クリックからCloudWatch Metrics画像化&通知など夢は膨らみますね!)
本稿が何かの役に立てば幸いです(クラメソ様風)。以上です。